BigMemory Go, the latest product offering from Terracotta. BigMemory Go lets you keep all of your application's data instantly available in your server's memory. Your application will respond promptly when you have your data closest to the application.
A general application will have a database storing GBs of data, which makes the application slow. BigMemory Go provides a brand new reliable, durable, crash resilient and, above all, fast storage, called Fast Restartable Store. Fast Restart feature provides the option to store a fully consistent copy of the in-memory data on the local disk at all times.
We generally use Database for bookkeeping, state-of-record, persistent data. With BigMemory Go, we provide durable persistent data store, which can handle any kind of shutdown - planned or unplanned. The next time your application starts up, all of the data that was in memory is still available and very quickly accessible.
We are here comparing the performance of mysql db (tuned to my best knowledge) with Ehcache hibernate 2nd level cache (w/ DB backend) and BigMemory store altogether. The sample application used here is classic Spring's PetClinic app (using hibernate), modified for simplicity and shed spring webflow, converted to standalone Java performance test. This app has a number of Owners which have Pets and corresponding Visits to the Clinic. The test initially creates a number of Owners with pets and visits and puts them to the storage. Then, it executes 10% read/write test for 30 mins.
The three cases considered here are
BigMemory Go FRS provides consistent 50 µs latency 99.99% of the time compared to 3 ms average latency for ehcache h2lc and 60 ms latency for MySQL db.With hibernate 2nd level cache we are surely making reads faster but still we have too much of hibernate and JPA transaction overhead to it.
A general application will have a database storing GBs of data, which makes the application slow. BigMemory Go provides a brand new reliable, durable, crash resilient and, above all, fast storage, called Fast Restartable Store. Fast Restart feature provides the option to store a fully consistent copy of the in-memory data on the local disk at all times.
We generally use Database for bookkeeping, state-of-record, persistent data. With BigMemory Go, we provide durable persistent data store, which can handle any kind of shutdown - planned or unplanned. The next time your application starts up, all of the data that was in memory is still available and very quickly accessible.
We are here comparing the performance of mysql db (tuned to my best knowledge) with Ehcache hibernate 2nd level cache (w/ DB backend) and BigMemory store altogether. The sample application used here is classic Spring's PetClinic app (using hibernate), modified for simplicity and shed spring webflow, converted to standalone Java performance test. This app has a number of Owners which have Pets and corresponding Visits to the Clinic. The test initially creates a number of Owners with pets and visits and puts them to the storage. Then, it executes 10% read/write test for 30 mins.
The three cases considered here are
- No Hibernate caching with DB
- Ehcache with BigMemory used as Hibernate 2nd level cache with DB backend.
- BigMemory Go Fast Restartable Store (FRS)
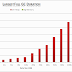
Performance comparison chart shows that BigMemory Go FRS outnumbers the competitors. With no hibernate and db transaction managements, it just runs faster than ever.
 |
| DB vs Ehcache h2lc vs BigMemory FRS |
BigMemory Go FRS provides consistent 50 µs latency 99.99% of the time compared to 3 ms average latency for ehcache h2lc and 60 ms latency for MySQL db.With hibernate 2nd level cache we are surely making reads faster but still we have too much of hibernate and JPA transaction overhead to it.